Precise and persistent overlay of large, complex 3D models/digital-twins on their (complete or partial) real life counter parts on a mixed reality (MR) head mounted device (HMD), such as the Microsoft HoloLens, enables critical enterprise use cases for design, training, assembly, and manufacturing.
Consider the design process of a car interior. The prevalent workflow is to do the initial design using CAD software on a PC, and then build a life scale model of that using a combination of hand cut foam and 3D printed plastic models. You then assemble it together inside a hollow car and evaluate the design. Based on review from the team and management, you make changes in the design, and repeat the whole process. It takes a lot of time and resources, and requires several iterations.
Now imagine the design process using MR, where you can render the 3D CAD model in full life size scale, with high fidelity (millions of polygons and high quality texture) and place it precisely (with the tolerance of a few millimeters) at the desired location inside the same car as above. You don’t have to put together the physical “mock-up” using foam and 3D printed models. The MR world can be shared by multiple users simultaneously across multiple HMDs. The review and feedback can be incorporated as design changes in the CAD file, and can be brought into the HMD in near real time. This would save a lot of time and resources, and shorten the iterations significantly.
In order to do this, we need to address two challenges:
- Render large complex models and scenes with 10s — 100s of millions of polygons, at ~60FPS with less than 20ms motion-to-photon latency.
- Rendering at the correct physical location (with respect to both the real and virtual worlds) with the correct scale, and accurate pose with sub-10mm accuracy.
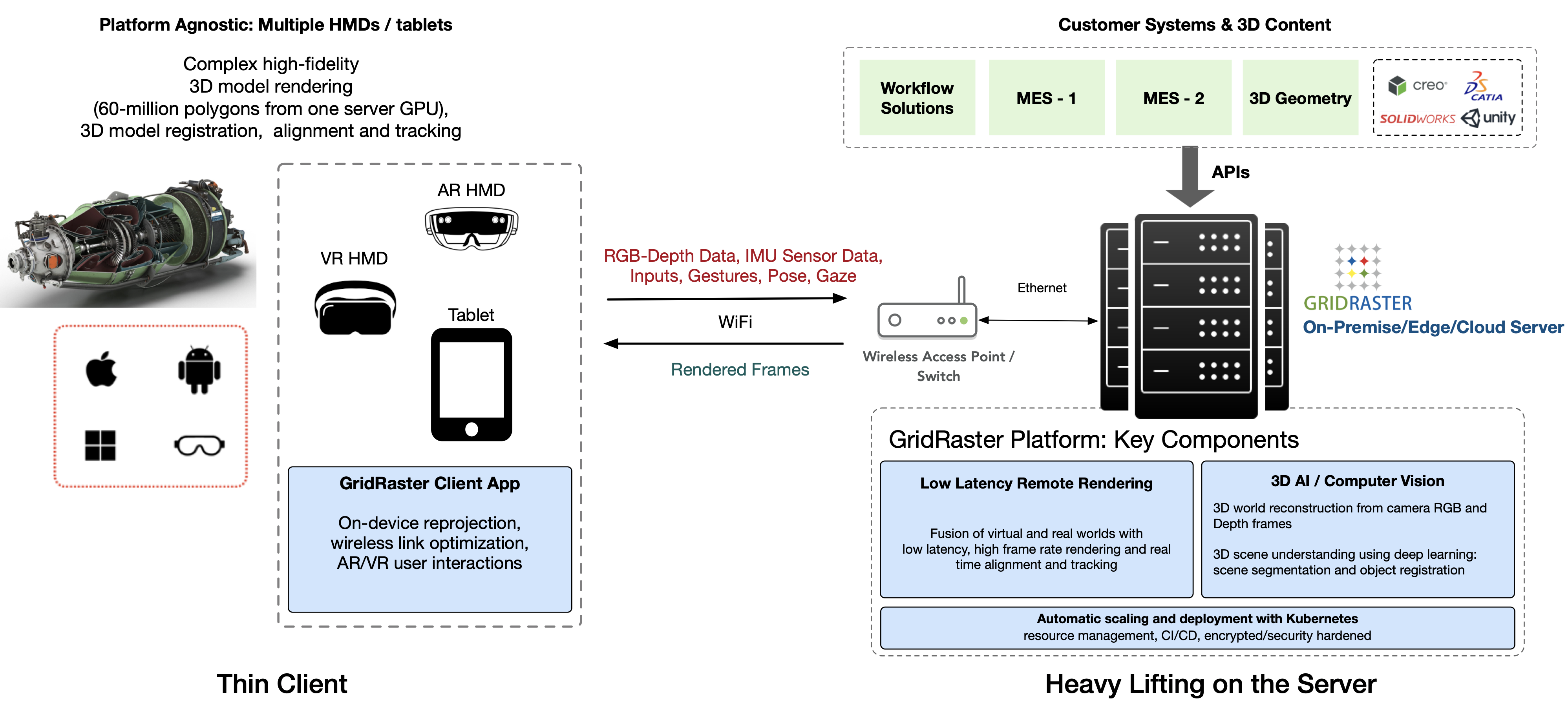
At GridRaster we achieve this using discrete GPUs from one or more servers, and deliver the rendered frames wirelessly, with ultra-low latency, to the head mounted displays (HMDs) such as the Microsoft HoloLens and the Oculus Quest.

In this article we focus on how we are using deep learning based 3D computer vision for accurate spatial mapping, and to determine where and in what scale and orientation (pose) do we place the virtual object(s).
3D Object Tracking and Model Overlay
Precise overlay of a 3D model or the digital twin with the actual object helps in industrial design, assembly, training, and also to catch any errors or defects in manufacturing. You can also use it track the object(s) and adjust the rendering as the work progresses.
Most on-device object tracking systems use 2D image and/or marker based tracking. This severely limits overlay accuracy in 3D because 2D tracking cannot estimate depth with high accuracy, and consequently the scale, and the pose. This means even though you can get what looks like a good match when looking from one angle and/or position, the overlay loses alignment as you move around in 6DOF. Also the object detection, identification and its scale and orientation estimation — called object registration — is achieved, in most cases, computationally or using simple computer vision methods with standard training libraries (examples: Google MediaPipe, VisionLib). This works well for regular and/or smaller and simpler objects such as hands, faces, cups, tables, chairs, wheels, regular geometry structures, etc. However for large, complex objects in enterprise use cases, labeled training data (more so in 3D) is not readily available. This makes it difficult, if not impossible, to use the 2D image based tracking to align, overlay, and persistently track the object and fuse the rendered model with it in 3D.
For 3D object tracking, we perform a detailed 3D scene understanding following the workflow as shown below. Given the computation limitations of the devices such as the HoloLens, the entire 3D processing is done on the server, with discrete high end GPUs, where the color and depth data (RGBD) from the HL cameras is used to reconstruct a full 3D point cloud with complete texture mapping. A fine mesh is then generated using this 3D depth map and the relation between different parts of the scene is established. Both the RGB data and the Depth data is used to segment the scene.

In the example above, the object of interest is the car dashboard. The GridRaster 3D AI module is able to isolate the dashboard from the rest of the scene by identifying its features using our deep learning based inference engine that matches it to the 3D model/digital-twin. It then automatically evaluates its distance and orientation, and generates the 3D transform for the object registration and renders the model precisely overlaying on top.
The rendered model can actually track any movement of the person or the object itself, in real time. This can be better illustrated with the example of a 3D printed Viking Lander model as shown below.

Summary
Deep learning based 3D AI allows us to identify 3D objects of arbitrary shape and size in various orientations with high accuracy in the 3D space. This approach is scalable with any arbitrary shape and is amenable to use in enterprise use cases requiring rendering overlay of complex 3D models and digital twins with their real world counterparts. This can also be scaled to register with partially completed structures with the complete 3D models, allowing for on-going construction and assembly. We achieve an accuracy of 1mm — 10mm in the object registration and rendering with our platform. The rendering accuracy is primarily limited by the device rendering capability. This approach to 3D object tracking will allow us to truly fuse the real and virtual worlds, opening up many applications including but not limited to: training with work instructions, defect and error detection in construction and assembly, and 3D design and engineering with life size rendering and overlay.